
信息隐藏研究展望
分类:计算机职称论文
时间:2022-05-07
摘 要:网络信息有 3 类,分别用于描述客观世界、记录人类行为、描述虚拟世界. 现有信息隐藏技术大多以第 1 类信息为载体,以轻微修改载体数据的方式进行隐蔽通信,并保证感知逼真与统计逼真. 该文在总结载体修改式信息隐藏的基础上,重点探讨以后两类信息为伪装的非载体修改式的新型信息隐藏方法,介绍了适合于特定载体类型的半构造式信息隐藏、完全构造式信息隐藏及行为信息隐藏的基本形式与代表性方法. 信息隐藏的形态在新的网络环境下将不断发展变化,各种信息媒介均可作为秘密信息的伪装,因此努力开展新型信息隐藏研究将大大有助于占据新时期信息战的主动地位.
关键词:信息隐藏;隐写;半构造式信息隐藏;构造式信息隐藏;行为信息隐藏
机密信息的安全传递是信息战及保密通信的核心任务. 作为信息安全传递的重要方式,信息隐藏(information hiding,或称隐写steganography) 将机密信息伪装为不引人注意的普通信息而达到隐蔽传输或隐蔽存储的目的,对国家安全与信息安全具有重要意义. 有时人们将用于版权保护的数字水印及其他分支也归为信息隐藏技术,而本文主要关注以伪装方式进行隐蔽通信的信息隐藏技术.
当前的信息隐藏技术大多以轻微修改载体数据(数字图像、视音频)的方式将秘密信息嵌入载体,将含密载体作为秘密信息的伪装. 个人计算机的普及与互联网上多媒体数据的泛滥为实施信息隐藏提供了便利条件,使信息隐藏得到了迅速发展,但近年来的发展速度有所放缓. 主要原因如下:1)在信息隐藏发展的同时,针对隐蔽信息的检测技术——又称隐写分析(steganalysis)——也得到了迅速发展. 该技术根据信息嵌入引起的载体数据统计异常来判断秘密信息是否存在,已对信息隐藏构成严重威胁;2)目前主流信息隐藏方法在修改载体数据时遵循“经验性地设定风险(失真)指标”再“利用编码方法最小化隐写总风险(失真)”的框架,鲜有突破性成果;3)相对而言,信息隐藏的理论研究显得滞后,不能为技术发展提供强有力的支撑.
随着信息技术的不断革新及网络环境的不断变化,只有不断突破信息对抗的固有模式并开拓新形态的信息作战方式,才能在网络空间中占据主动地位. 网络信息可以分为3大类:1)描述客观世界的信息,2)记录人类行为的信息,3)描述想象世界(虚构世界)的信息. 第1类信息曾经是网络信息的主流,而以感知逼真与统计逼真为要求的传统信息隐藏也正是以第1类信息(例如多媒体数据)为载体的,但随着物联网、大数据、社交网络、虚拟现实等技术的发展,后两类信息也必然飞速增长,必须积极探讨以后两类信息为伪装的信息隐藏新方式:行为信息隐藏与构造式的信息隐藏.
1 信息隐藏研究现状
信息隐藏研究始于20世纪90年代中期,并于21世纪得到了迅速发展,主要通过修改载体数据来实现信息隐藏. 与此同时,针对信息隐藏的检测技术(隐写分析)也不断进步. 该技术根据载体数据的统计异常察觉秘密信息,进而估计秘密数据量、隐藏方式及密钥,是信息隐藏的主要威胁. 本节简述信息隐藏研究的现状.
早期的信息隐藏与检测 早期的信息隐藏方法大多能保证BMP、JPEG、GIF 等格式载体图像的视觉质量,但对载体数据统计特性考虑不多,如最不重要位 (LSB)替换隐写、最佳奇偶分配(OPA)隐写等. 检测者可根据直方图异常、JPEG分块效应、调色板奇异颜色等异常现象有效击破这些早期的隐藏方法或工具(SecureEngine、Jsteg、JPHS、OutGuess 等) [1-2] . 随后,研究者提出了一些可维持某些统计特征无异常的信息隐藏方法,但安全性仍不令人满意. 例如,LSB 匹配方法避免了统计不对称性和直方图异常,但检测者可根据直方图Fourier域质心位置的变化[3]、最低两层位平面的统计特征变化[4]或解压图像的噪声特征异常[5]来察觉秘密信息;Model-Based 方法可维持原始分布模型[6],但与理想模型的过分吻合反而引起怀疑[7] . 检测者还可进一步估计秘密信息嵌入量[8],且准确性不断提高[9] . 可同时检测多种隐藏方法的隐写分析被称为通用分析或盲检测. 通用分析不再依据少量敏感统计特性判断载体是否含密,而是从大量原始样本与含密载体样本中提取特征向量再训练分类器,然后区分原始载体与含密载体[10] . 早期用于隐写分析的特征有图像质量测度[11]、DCT与马尔科夫特征[12]、高阶统计特征[13]等,分类方法包括神经网络[14]、支持向量机[15]、几何模型[16]等.
信息隐藏安全性 理想的信息隐藏应使含密载体在整个载体空间的分布与原始载体分布完全一致. 两种分布之间的差异程度可用KL散度(KL divergence)度量,该指标也可用于衡量信息隐藏系统安全性[17] . 然而,载体空间异常巨大,研究者往往在简化数据统计模型后再讨论安全性,如假定载体采样数据服从独立同分布[18]、或将载体数据空间投射为统计特征空间[19] . 与KL divergence 相比,最大均值差异(maximum mean discrepancy, MMD)更易于计算,且在高维空间比较稳定,也可作为安全性指标[20];研究者们还利用Fisher信息量给出了安全嵌入容量并对其进行优化[21-23] . 当隐藏者知晓隐写分析方法时,可采取相应措施使隐写分析失效,如文献[24] 利用凸集投影法获得失真小且高阶特征无异常的含密图像,对抗文献[13] 中的隐写分析方法;文献[25] 将图像数据分为两部分:一部分用于隐藏秘密信息,另一部分用于校正隐藏引起的统计特征变化,可抵抗文献[12] 中利用274维特征的隐写分析方法. 然而,信息隐藏必然引起载体数据变化,如选用其他统计特征进行分析,仍可察觉秘密信息. 文献[25] 讨论了统计特征完备性对隐写分析的帮助.
隐写编码 隐写编码可用更少的改动嵌入同等数据量的秘密信息,是提高安全性的重要手段. 根据线性分组码可反向构造一系列隐写编码方法[26],并发展快速算法[27];根据卷积码可构造动态游动方式的隐写编码方法[28-29] . 当载体数据变化方向也用于负载秘密信息时,编码性能可进一步提高[30-32],文献[33] 给出了隐写编码在一定失真条件下的性能理论极限. 湿纸编码是另一类信息隐藏手段,隐藏者可自由选择嵌入位置,而接收方不必知晓嵌入位置也可提取秘密信息[34] . 文献[35] 结合湿纸编码与隐写编码,构造了双层隐写编码方法,并证明了双层编码结构在性能提升方面可达到理论极限[36] . 集中多种编码方法的优势还可以提高总体性能[37] . 文献[38] 利用低密度生成矩阵构造了性能接近理论极限的二元编码方法,文献[39] 提出了一种新的编码结构,可由文献[38] 中的少数优质方法派生出一族性能优异的隐写编码方法,所得结果的性能目前最接近二元嵌入的理论极限[40-41] . 学术界对载体数据调整幅度为2或3时的隐写编码方法也进行了研究[42] .
STC 框架 隐写编码提升安全性的策略是“改得少”,而安全隐藏不但要改得少,还要改得好,即基于载体内容自适应地选择修改位置及修改方式. 早期PVD方法在差值较大的像素对中嵌入更多信息[43-45],就是一种自适应的隐藏方法,但直方图异常会暴露秘密信息[46] . 上文提及的湿纸编码也支持秘密信息的自适应嵌入[34,47] . 作为隐写编码和湿纸编码的拓展,Filler与Fridrich 于2010年提出了基于STC (Syndrome-Trellis codes) 的信息隐藏框架[48] . 该框架中定义了一般形式的失真函数,并在嵌入秘密信息的条件下最小化失真函数值. STC主要有两方面的贡献:一是使用了卷积码的校验阵,从而使上述极小化问题可以在二元嵌入条件下快速求解,二是构造了一种双层二元嵌入方法来快速实现±1嵌入,并推向实际应用. STC 框架将信息隐藏分解为两部分:一是设计失真函数,以合理度量载体数据变换引起的失真(风险);二是利用编码技术实现总失真的最小化. 由于STC 方法较好地解决了第2部分问题,设计基于图像内容的自适应隐藏方法变得非常方便,从而使信息隐藏研究进入了一个新阶段. 这个阶段主要集中在失真代价函数的设计,如HUGO、WOW、UNIWARD、HILL等[49-54] . 与经验地设计失真代价函数不同,文献[55] 将安全性度量指标KL divergence 表征为失真代价的函数,进而寻找最优失真代价的设计方法以期优化隐写安全性度量,并给出了合理选择失真代价函数的理论依据和未来的探索方向. 此外,文献[56] 考虑了更加通用的失真函数以期将相邻像素点之间的协同变化对载体的影响也考虑在内,但只能得到次优解而并没有真正解决该问题. 后续实验也表明,基于文献[56] 的工作没有得到比STC 更好的隐写方法[57] . 文献[58] 进一步拓展了文献[55] 的方法,并提出一种改进的图像模型参数估计方法用于隐写设计,其性能略优于 HILL[53]. STC 框架也使JPEG图像信息隐藏研究大为改观,与早期较为成功的JPEG信息隐藏方法(如F5、PQ及其改进、nsF5、YASS 及其改进)不同,目前主流JPEG信息隐藏方法是在DCT系数上应用STC,其核心问题也是合理设计失真代价函数[59-64] .
相关知识推荐:论文质量报告怎么弄
隐写分析的发展 隐写分析技术随着信息隐藏的发展而发展,当前主流隐写分析都是先进行特征提取再利用训练集进行学习分类. JPEG图像隐写分析特征从23维DCT域特征[65]、18维二元相似性度量特征[66]发展到193维扩展DCT特征[67]、324维Markov特征[68]、432维小波系数幅度和相位特征[69] . 研究表明,小波系数的特征函数矩特征的性能更好[70] . 利用笛卡尔校准方法[71]对Markov特征和扩展DCT特征进行校准,分别构造了648维的CC-SHI 特征和548维的CC-PEV特征. 在空域中根据像素差分平面计算一阶二阶的条件概率,分别提取578维和686维的SPAM 特征[72] . 文献[73] 在DCT系数平面上计算差分相邻系数的联合密度,据此设计出216维特征,在大大降低特征维数的同时保持了性能上的优势. 隐写分析在分类时往往选择成熟的分类器,如神经网络、SVM 等. 这些分类器通过非线性变换对特征空间进行高维映射,显著增加了计算复杂性,因此常用于低维特征. 隐写分析特征的高维化是近年来重要的发展趋势,如将CC-PEV特征和SPAM 特征合并构造交叉域的1 234维特征[74] . 文献[75] 利用共生矩阵构造了7 850维的CFstar特征,其检测性能超越了以往任何方法. 文献[76] 根据DCT系数联合分布的多个子模型构造出11 255 维的DCT域特征,利用笛卡尔校准模型构造22 510维的变换域富模型(rich model, RM)特征. 文献[77] 在空域中分别利用线性和非线性计算量化图像的噪声残差,并联合各个子模型得到了34 671 维的空域富模型特征. 为解决高维特征带来的计算量激增问题,可选择简单分类(如Fisher线性分类器)进行集成判决,还可通过降维[78]、分类结果的加权集成[79]进一步提高分析准确率. 文献[80] 通过64个三角函数滤波器将隐写变化体现在不同尺度的差分信息中,形成 8 000 维DCTR特征用于隐写分析,并说明了DCTR与CC-JRM 的异构融合特征比单一特征集性能更好. 文献[81-86] 使用“图像建模+假设检验”的方法进行隐写分析,该类方法先验地假设载体图像满足某个统计分布,然后根据具体的嵌入方法建立含密图像所满足的统计模型,最后利用所假设的检验理论中的似然比检验方法建立最优检测子,以实现隐写分析. 与此前的隐写分析工作有很大不同,该类方法保证了统计意义下检测子的最优性,并经实验证明能提升隐写分析性能.
多载体信息隐藏与联合分析 如果秘密信息量较大,隐藏者不可避免地利用多个载体负载秘密信息,而检测者则要判断一批载体中是否含有秘密信息. 这类问题被称作多载体信息隐藏/批量隐藏(batch steganography, BS)和联合分析(pooled steganalysis, PS). Ker研究了可疑载体计数分析、平均联合分析、广义似然率测试3种不同策略下的情况[87],以及可疑载体计数分析中关于阈值选取的博弈均衡[88],并证明了多载体安全嵌入容量正比于载体数量的平方根而非载体数量[89],单载体安全嵌入容量正比于载体大小的平方根[90-91],进而给出最小化KL divergence 的多载体隐藏策略[92-93] . 文献 [94] 尝试解决多参与者的联合分析问题,利用最大均值差异(MMD) 方法度量特征集之间的距离,通过层级聚类识别隐藏者. 文献[95] 以局部异常因子(local outlier factor)代替层级聚类,所得检测结果更准确. 文献[96-97] 给出了最大贪婪、最大随机、线性、均值、平方根等5种嵌入策略以提高对抗联合分析的能力. 近期亦有学者将联合分析用于社交网络图像[98] .
基于载体选择与合成的信息隐藏 上述方法都是通过修改载体数据进行信息隐藏,而其他方式的信息隐藏非常少见. 文献[99] 讨论了基于载体选择与合成的信息隐藏方式:在载体选择的信息隐藏方式中,隐藏者根据秘密信息在正常图像库中选择图像发送,接收者计算图像Hash 得到秘密信息,这种方法因负载量太低而无法推广到实际应用中;在载体合成的信息隐藏方式中,隐藏者根据秘密信息将图像局部内容的不同曝光版本拼成含密图像,接收者计算图像局部Hash 得到秘密信息. 由于实际场景中很难获得一个信号的多次采样(曝光版本),这种方法也不实用[100] . 文献[101]提出了一种不需原始载体的文本信息隐藏方法,利用mimic函数将秘密信息伪装成类似垃圾邮件的文本,但也容易引起检测者的警觉.
文献[102-105]对信息隐藏进行了深入而系统的研究,所获成果具有重影响,已从10余年前的“跟跑”发展为近年来的“并跑”,并对突破修改式的信息隐藏发展瓶颈有许多有益的探索. 本文作者将另文专述对抗检测、理论研究和突破STC 框架等问题,下面重点讨论非修改方式的信息隐藏.
2 半构造式信息隐藏
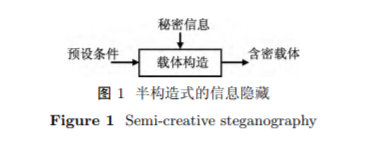
构造式信息隐藏,是指在不预先指定原始载体的情况下,由秘密信息按照一定规则直接生成含密载体,而含密载体可以不表示真实的客观世界,但与正常内容相比应具有不可区分性. 已有的半构造式信息隐藏方法往往事先给出载体构造的预设条件,然后根据秘密信息并遵循一定的构造规则生成含密载体. 含密载体属于特定类型,如图1所示.
2.1 纹理合成信息隐藏
纹理合成技术可由一小块样本纹理图像生成大幅纹理图像[106-109],纹理合成信息隐藏即在纹理合成的过程中实施信息隐藏,最终生成的大幅纹理图像是与秘密信息有关的. Otrori和Kuriyama最先提出在纹理合成过程实现数据嵌入的思路[110-111],该方法首先在样本图像中选择若干彩色点,然后使用LBP 码(local binary pattern)来映射二值数据和彩色点之间的关系,接着根据秘密信息内容预先确定若干位置的彩色点,最后从样本图像中寻找合适内容合成大幅纹理图. 图2是一个示例,其中图(a)为样本图像,图(b)是根据秘密信息在白纸上描绘的LBP 码对应的彩色点,其中包含25 byte的秘密数据,图(c)是由图(b)生成的大幅纹理图像.
文献[112]指出Otrori和Kuriyama的方案有容量低和提取误码的局限,于是提出了新的解决方案,可实现大容量无误码的信息隐藏. 该方法在样本图像中逐点移动获得多个候选块,将每一个候选块分为内核(kernel)和外围(border)两部分,比较每一个候选块的外围与其他候选块外围之间的匹配程度,由大到小建立直接与二进制数据相映射的索引表. 在纹理合成时用候选块填充大幅图像的空白部分,具体选取哪个候选块取决于秘密数据,最终可得到一幅由秘密数据决定的纹理图像. 最新研究表明,该方法仍然存在安全漏洞[113] . 因为生成的含密纹理图像完整地保存了原始样本图像的所有分块,所以攻击者可通过分析含密图像中块与块之间的缝补(quilting)关系重建原始样本纹理图案,进而重建候选块索引并提取秘密信息.——论文作者:张新鹏, 钱振兴, 李 晟
* 稍后学术顾问联系您




