0
发表咨询在线!

摘 要:定性比较分析(QualitativeComparativeAnalysis)正在 西方 社 会 科 学 研 究 领 域悄然兴起。表面上看这只是一种研究社会科学的技术性手段,但实质上它代表着一种全新的研究逻辑,可以作为传统的定性研究和定量研究的重要补充。定性比较分析的基本逻辑是:基于布尔代数原理,通过讨论集合间的隶属关系发掘多个案例所展现的普遍特征。它与传统的定量研究相比主要有三个差异:(1)聚焦研究结果变量和自变量之间的非对称性关系,突破了传统定量研究基于相关系数的对称性思维局限;(2)认为达到同样的结果可以有多条路径,而每条路径都是不同的相关因素组合,这突破了传统定量研究拘泥于单一模型验证独立变量显著性的思维套路;(3)以模糊集合代替对变量的精确性测量,使研究结论更加符合真实世界的要求和客观规律。结合经济管理学等领域的具体案例,文章还阐述了定性比较分析缘何可以成为传统定性和定量研究以外的第三种研究思想,并提出了该方法的研究局限和在经济管理学领域的应用展望。
关键词:定性比较分析;研究逻辑;经济管理
一、引 言
在社会科学研究中,关于定性方法和定量方法孰优孰劣之争由来已久。定性比较分析最原始的思想就在这一片争论声中,于20世纪80年代由美国社会学家 CharlesRagin首次提出。当时的学术界认为,定性比较分析只是提供了一个折中的路线,机智地避开了定性与定量这两种方法各自的缺陷(Ragin,1987)。然而,综观定性比较分析近30年来的发展和应用,它带给社会科学研究者的已远远不只是一种技术性手段,而更是一种全新的研究逻辑(Rihoux,2006;Berg-Schlosser等,2008;Schneider和 Wagemann,2009)。它适合研究包括经济学和管理学在内的社会科学,能够成为主流的社会科学研究方法之一。但可惜的是,目前的社会科学研究方法,大体只有定性研究和定量研究两大类,而其中的定量研究又普遍都是基于回归分析的定量方法,无论是“多元回归”,还是“结构方程”(SEM),本质都是基于变量的回归。研究方法的单一性直接导致了研究逻辑的单一性,以至于但凡涉及社会科学的定量研究,研究人员都循规蹈矩地以寻找相关变量在大样本统计上的显著性作为研究的基本逻辑。而传统的定性研究则都是基于相关个案的归纳或者逻辑演绎,无法验证结论的普遍适用性,这是传统定性研究的短板。定性比较分析的出现调和了传统定性和定量研究的特点,形成了一种新的社会科学研究思想(Ragin,2008)。定性比较分析方法在国外社会科学研究领域的应用已相当广泛(Ragin,1987;DeMeur和 Rihoux,2002;Rihoux,2003;Ra-gin和 Rihoux,2004),但在我国却仍然是一新鲜事物,提及定性比较分析方法的学术论文仅有三篇,作者分别是黄荣贵和桂勇(2009)、倪宁和杨玉红(2009)、李健和西宝(2012)。
本文旨在解析定性比较分析的研究逻辑,以期望对经济管理学的研究提供源自方法论的思想启迪。文章研究安排如下:首先,根据 Gigerenzer(1991)对研究工具的“非独立性”的阐述,指出了定性比较分析研究逻辑的三大基本特征:第一,将研究问题抽象为不同的因素组合,通过因素之间的集合隶属关系来研究社会问题。集合隶属关系是一种非对称关系,因此定性比较分析承认了非对称关系的普遍存在性;第二,非对称性关系的存在,使得达到同样的结果可以有多条路径选择,定性比较分析旨在找出这些路径,因此它承认了社会现象背后隐含的多重并发条件的存在性;第三,整合了定性研究的特点,关注因素的质变而非量变,因此其聚焦的是因素的“有效变化”。其次,通过理论分析并结合经济管理学的实际案例,阐述定性比较分析研究逻辑的基本特征。再次,分析了定性比较分析对经济管理学研究的启示。最后,基于文献研究和实际运用该方法的感受指出了定性比较分析的使用局限性。由于“回归分析”已为广大社会科学研究者所熟悉,为了更好地分析定性比较分析的特点,文章主要将其与基于回归分析的传统定量研究方法进行对比。为方便起见,如无特别交代,文中提及的“传统的定量研究”皆指以“回归分析”为主要方法的定量研究。
二、研究工具影响研究逻辑
Gigerenzer(1991)将研究工具影响研究逻辑阐述为研究工具的“非中立性”。研究者选用不同的研究工具将导致对同一个研究问题,可以着力于不同的研究目标。传统的定量研究的目标几乎都是验证相关自变量对结果变量即因变量在统计上是否显著,研究逻辑是:首先确定研究的因变量和有关的自变量,然后经过回归验证每个自变量对因变量的影响是否显著,通过“回归分析”排除他因,找到每个自变量对结果变量的真实影响。反观传统的定性研究,其研究逻辑是:对一个或者多个相关案例,通过全面描述归纳其展现出的规律性,但是这只是基于研究人员能够观察到的有限个案而发现的,无法保证其结论的普遍适用性;因为传统的案例研究在进行多个案例比较时,并未尝试进行科学的统计性验证。结论缺乏普遍适用性是传统案例研究的劣势(Ragin和 Becker,1992;Gerring,2004)。
定性比较分析在一定程度上综合了传统定性研究的特点和传统定量研究的优势,以讨论集合间的隶属关系为主要手段,基于布尔代数的原理,发掘多个案例所展现的普遍性特征。Ragin认为,通过集合关系来研究社会科学是合适的,因为所有社会科学的论断都是基于“系动词表述”,而系动词则反映了集合关系。例如,“发达国家都是民主国家”这一论断,集合关系表达为:发达国家的集合是民主国家集合的子集(Ragin,2008);又例如,“融洽的雇主雇员关系可以让企业绩效提高”,集合关系表述为:雇主雇员关系融洽这一集合是企业高绩效集合的子集;而“经济危机爆发前的特征表现为生产过剩和资产泡沫化严重”,集合关系则表述为:经济危机爆发这一集合是生产过剩和资产泡沫化严重这两个集合交集的子集。简单来说,定性比较分析的研究逻辑是通过一定数量的案例之间的比较,找到集合间的普遍性隶属关系,其研究结论相比传统定性研究具有更高的效度。对比而言,传统定量研究“找变量-建模型-假设检验”的研究逻辑,要求研究人员将可能影响结果的相关变量都放入模型中进行统计回归,这种做法的科学性虽然毋庸置疑,但其中一个重要假设前提是承认自变量和结果变量间只存在两种可能:一是没有相关关系,二是有相关关系。事实上许多定量研究的实证结果往往介于这两者之间,严格而言,是违背其设定的假设前提的。现实中固然存在大量的“对称性”相关关系,但也存在广泛的“非对称性”集合关系。
三、定性比较分析研究逻辑的基本特征
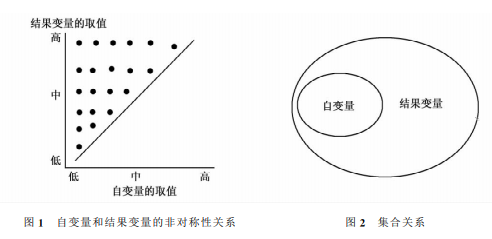
(一)非对称性关系普遍存在。承认现实世界中广泛存在着非对称性关系是定性比较分析研究逻辑的基本特征之一。何谓非对称性关系?从逻辑学角度讲,所有的“必要非充分条件”和“充分非必要条件”都描述一种非对称性关系。若自变量和结果变量的取值如图1所示,可以很直观地看出,当自变量取值高时,结果变量的取值也高;但是,当自变量的取值低时,结果变量的取值未必就低;因此,这种非对称性关系体现为自变量是结果变量的“充分非必要条件”。假设结果变量是考试成绩,自变量是IQ(智商),“充分非必要条件”即指:若IQ高,考试成绩一定高,但IQ 低考试成绩也未必就低(愚钝的学生通过刻苦努力成绩也可以很高)。
需要指出的是,定性比较分析不使用变量一词,而使用“因素(Antecedent)”代替变量,以“因素”表示其隶属于某一个集合的程度。如上例中提到的IQ 高,则可以用 隶 属 于“高IQ”这一集合的程度来表示。因此,图1所示的非对称性关系,在定性比较分析中,以集合的形式描述为自变量所代表的集合是结果变量所代表的集合的子集,如图2所示。
但是,传统的定量研究大多聚焦如图3所示的对称性关系。由图3可见,自变量高时,结果变量的取值也高;自变量低时,结果变量的取值也低。因为回归分析是通过变量间的相关系数所得到的,而相关性则是一种对称性关系。如果仅从相关性的结果来看,图1的对称性不明显,但是其非对称性关系则非常明显。
传统的定量研究在处理现实世界中广泛存在的非对称性关系时,显得乏善可陈。比如,在研究财富和幸福度的关系问题上,传统的定量研究大多认为,财富和幸福度之间存在显著的正相关关系,美国学者 Hagerty和 Veenhoven(2003)通过对相关国家的数据进行回归分析也验证了这一点。但是,Fischer(2008)却发现随着美国人财富的持续增加,其幸福度 并没有相应地持续增加,Fischer称其为幸福悖论。基于变量回归的研究假设为:财富和幸福度要么没关系,要么存在此消彼长或此高彼涨的相关关系。然而,财富和幸福度之间也可能图3自变量和结果变量的对称性关系存在着非对称性关系,即财富是 幸 福 的“必 要 但 非 充 分”条件。也就是说,没有财富一定不会幸福,但是,当财富作为幸福的必要条件的“阈值”达 到 以 后,财富还需要和其他相关因素结合(因素组合)才能获得相应的幸福。该假设在真实的环境中是基本合理的,中 国 有 句 俗 语“贫 贱 夫 妻 百 事哀”,即是描述了财富和幸福的这种非对称性关系;当然,其否命题“越富贵的夫妻越幸福”则不成立。在中国传统文化中也有许多类似的例证,比如隋朝的颜之推在《颜 氏 家 训》中反复阐述财富和幸福不是正相关关系,并叮嘱他的后代不要把市井的斤斤计较带入婚姻中,不 要 攀 高 枝,否 则,虽然得到了物质 财 富,但 却 自 取 其 辱,毫 无 幸 福 可 言。“近 世嫁娶,遂有卖女纳财,买妇输绢,比量父祖,计较锱铢,责多还少,市井无异。或猥婿在门,或傲妇擅室,贪荣求利,反招羞耻,可不慎欤!”(《颜氏家训治家第五》)。
诚然,在不同的路径下,的确会有某些因素处于某种核心位置,例如,达到C 结果的两条路径X1●X2●~X3和 X2●X4●X5,其中 X2因素为两条路径所共享,图5直观表现图5 不同的路径和其因素组合为 X2处于内圈,外圈的因素组合是可以变动的。
但即使 X2因素占据核心位置,也并不能因此而认为该因素就可以单独影响结果,它需要和不同的其他因素的组合才能发生作用。Fiss(2007)在研究高绩效的企业的成因时,通过定性比较分析方法发现不能简单地将问题归结为哪种类型的企业,哪种市场策略,或者哪种组织架构更易获得高绩效。因为不同类 型 的 企 业,如市场的防守方(Defender)、进 攻 方(Pro-spector)以及中间类 型(Analyzer),需要和不同的市场策略以及不同类型的组织架构相结合,才能获得高绩效。比如市场的防守方一般属于成熟的大公司,组织结构更趋于稳定和集中,拥有市场占有率的优势,比较而言,这类公司所选择的市场策略如果是成本领先策略和适度的差异化可以确保企业的高绩效。Fiss特别强调,通过定性比较分析研究企业绩效时,我们不应该大而化之地认为哪种市场策略可以带来企业的高绩效,而应该研究不同市场策略组合带来的绩效差异。同样的原理,在研究管理者性格和企业成败的关系时,企业家会问:优秀的管理者应具备何种性格特征?这类问题具有一定的误导性,因为任何一种性格的管理者都有可能成为优秀的管理者,关键在于这种性格应该和哪种类型的企业以及哪种企业文化相组合才能产生有效的反应。显然,定性比较分析关注因素组合所形成的路径,而非独立变量,使其突破了传统定量研究聚焦于独立变量显著性的窠臼。
(三)使用模糊集合聚焦有效变化。上文提及,定性比较分析对所要研究的因素不称之为“变量”,因为变量是通过测量来体现出它的变化,而定性比较分析将所要研究的因素对照某一指定的集合进行“校准”(Calibration),以表示因素隶属于这一集合的程度。
有两种校准方法:二元校准法和基于模糊集合的校准方法。二元校准法以0和1代表两端,0代表“完全不属于”该集合,而1代表“完全属于”该集合。而基于模糊集合的校准法则将0到1连续化,以代表隶属程度的不同,这成为定性比较分析研究逻辑的第三大特征。
从表面上看,对变量的“测量”和对集合的“校准”,只是两种不同的数据处理手段,但却体现了定性比较分析的特征,也即:测量记录的是客观性变化,而校准记录的是从量变到质变的“有效性变化”。例如,Melamed和Bozionelos(1992)在对男性职员的身高和升职情况进行回归分析后发现两者具有显著的相关性,也就是说,在其他条件基本都一样的情况下,身高越高的男性相对更容易获得升职的机会。但基于常识,这种身高的差异只会在有效性变化范围之内才能体现出优势,在一般的公司,很难认为一个身高205厘米的职员相对于一个身高195厘米的职员会有任何升职的优势,因为他们都同时完全隶属于高个子集合,但是一个180厘米的职员相比一个170厘米的职员可能就有升职优势,因为他们处在“非高个子集合”往“高个子集合”过渡的“有效变化”范围内。因此,195厘米到205厘米,在测量上的变化是10厘米,但在校准上的变化却是0;而170厘米到180厘米,在测量上的变化也是10厘米,但在校准上的变化一定大于0。另外,在经济学研究国家贫富时,若以GDP作为测量,挪威和瑞士的人均GDP 肯定是不同的,但若基于富裕国家集合进行校准,可以认为它们都完全隶属于富裕国家集合。
需要指出的是,校准不同于回归分析中的序列变量(ordinalvariable),序列变量是基于排序来分组,不考虑它对某一集合的隶属程度,而校准需要研究人员进行模糊化处理,是基于对案例本身的深刻理解和对研究背景的熟悉而得出的结果(Ragin和 Becker,1992)。
模糊集合的思维由Zadah(1965)在20世纪60年代率先提出,他认为,社会科学研究不同于自然科学,其复杂性比自然科学大很多,而复杂的东西往往是难以精确化的。这其中蕴含着一种“互克性原理”,也称“不相容的原理”,即当一个系统的复杂性增加时,我们使它精确化的能力就会减少,达到一定限度时,复杂性跟精确性就会相互排斥。在类似的情况下,生物学、心理学、社会学和经济管理学等都不建议用特别精确的方法量化他们的规律。因此,模糊集合应该受到足够的重视。——论文作者:夏 鑫1,何建民 1,刘嘉毅2
本文来源于:《财经研究》创刊于1956年9月,本刊注重理论联系实际,着重研究和阐述我国改革开放和现代化经济建设的重大理论和实际问题,积极探索具有中国特色的社会主义经济的发展规律。
* 稍后学术顾问联系您







