
基于 Hadoop 的智能电网时序大数据处理方法
分类:计算机职称论文
时间:2022-04-09
摘要: 为了提高电网数据处理的安全性和效率,提出基于 Hadoop 的智能电网时序大数据处理方法。依据智能电网时序大数据简析,结合 Map、Reduce 及 Partition 三个函数具备的过滤器和工厂法以及监听器等一系列模式,实现数据清洗处理。依据分布式计算思想,结合近邻分类法和 Map - Reduce 模型设计的并行分类混合法,实现数据分类处理。对分类数据进行安全存储,通过消息摘要算法针对需要存储的智能电网时序大数据生成相应数字摘要; 根据密钥生成函数获取随机密钥,同时利用上述密钥针对待存储数据实行加密,获取对应密文。针对获取的随机密钥实行信息隐藏处理; 把密文存储至云中; 当密文成功存储至云之后,把获取的密钥和数字摘要两种信息并同文件名至 HBase 中,实现数据存储。仿真结果表明,上述方法具有较强的安全性与时效性。
关键词: 智能电网; 时序大数据; 处理
1 引言
分布全网的各种类型信息数据采集装置生成了大规模时序数据,关于此类数据的存储、处理等均面临着严峻的挑战[1 - 3]。由此,针对智能电网中的时序大数据进行高效处理有着十分关键的作用和重要的意义。
曲朝阳[4]等人将 Spark 应用至电力设备监测数据可视化处理中。过程中,以快速提取大数据环境下电力监测数据整体状态信息为目的,基于 Spark 大数据计算平台,设计并构建了设备状态评价指标体系和模糊 C 均值聚类算法下的电力设备状态数据提取法。对数据具备的多维和时序等特征,构建三维平行散点图,实现数据可视化展示,完成电力设备状态信息可视化处理。喻宜[5]等人以解决电力大数据背景下大规模时序数据无法高效处理的问题为目的,结合当前分布式技术框架设计并构建真正意义上的 GAIA 大规模时序数据管控平台,以此保障系统具备稳定性与可靠性。根据具备可配置层次关系架构的模型中心解决大规模测点管控问题。依据时间分片和事件驱动下前置数据采集平台解决大规模终端实时数据采集处理问题。张宇航[6]等人指出,智能电网具备的数字化建设能够提供大规模数据信息,深度学习发展能够为数据价值提取提供可靠途径。在研究过程中,先对深度学习发展史和基础结构进行分析,并归纳了深度学习理论基础与技术体系; 然后与电力系统实际需要相结合,将图像数据和时空数据了两种类型的数据当作基础,综合描述了深度学习在电力数据处理中的应用和具体价值,同时给出了一些相关发展建议。
电网时序数据具有规模大、实时性要求高和访问方式多变等特点,对其进行处理需要注意的点比较多,其中包含安全性、效率。为此,提出基于 Hadoop 的智能电网时序大数据处理方法。
2 基于 Hadoop 的智能电网时序大数据处理
2. 1 智能电网时序大数据
实际生活中,智能电网时序大数据通常指的是根据设备或者仪表产生,利用传感器进行采集,和某个对象或者设备存在具体关联性,在事件上先后关联的一类数据。详细如图 1 所示,其中包含的电压等即为典型时序数据。
2. 2 数据清洗
在基于 Hadoop 的智能电网时序大数据处理方法中,大数据清洗是不可或缺的一个步骤。针对 Map 和 Reduce 及 Partition 三个函数均进行了精心设计,通过 xml 配置,实现对应的清洗类动态收集和清洗规则设定等。
数据清洗过程中,Map 函数是该架构中最为核心的部分,把数据由原始状态清洗到可利用数据。Map 设计中使用了过滤器和工厂法以及监听器等一系列模式,能够使清洗系统具备良好的扩展性。图 2 为 Map 函数核心设计示意图。
图 2 中,LogProcess 类主要负责 Map 阶段基础性的配置文件前期准备以及使用方案调用 Handler 类,梳理实际数据处理逻辑。其中,Handler 类为处理逻辑中实际控制类,均需在 Map 阶段初始化环节完成。实际处理过程中根据 Handler 调用图 2 中的流程部分完成: 利用 FilterChain 以相似管道的模式进行逐步解析与清洗,FilterChain 主要作用为配置过滤条件。在 Map 设计过程中,所有类都使用了可配置方式,能够基于实际数据清洗需求任意替换与修改。
在日志处理过程中,原始日志利用 JournalClean 类实现基础处理,从而生成部分基础字段,同时以 table 形式保存至 Journal,以此构成 Journal 日志类,把该类在过滤器链中依据具体要求下的逻辑实行解析,生成最终所需字段,利用 JournalWriter 日志写入相应文件,将最终数据输出。
2. 3 数据分类
依据分布式计算思想,解决智能电网时序大数据分类问题,根据近邻分类法具备的优势,结合 Map - Reduce 模型和其融合设计一个并行的分类混合法—PCHA。
输入: 要实现 PCHA 算法,构建接口提供 Map 函数与Reduce 函数,并表明输入、输出以及其它运行参数。利用输入环节把大数据集合分解成若干个独立的数据集合,便于接下来的处理,在此设置为M'份数据集合,提交至 JobTracker 之后,利用对应的 TaskTracker 执行任务。
Map: 在 Map - Reduce 模型中通常分解一个大数据集变为小数据集合,该环节是针对每一组分解数据集合的{ ke, va } 对实行映射操作,此时 TaskTracker 调用空闲数据资源执行 Map 与 Reduce 任务。Map 过程重点是针对分类数据集合实行键值映射操作,任务基于各属性规范化操作,同时依据重要性并获得加权欧式距离结果,获取( ( 节点,属性) ,( 相似程度) ) 键值对,基于相似程度实现归类。
Reduce: 该环节主要责任为遍历所有 Map 环节处理之后生成的中间结果集合,依据同一( 节点,属性) 值的排序和归纳,统一将( ( 节点,属性) ,( 相似程度) ) 输出,基于相似程度实现并行分类。
输出: 该环节是和输入环节相呼应的,也就是功能为针对 Reduce 环节的输出结果集合实行输出操作,同时将输出保存到指定位置,该环节获取的即为 PCHA 算法运行所得的分类结果集合,方便下一步安全存储处理。
2. 4 数据安全存储
在基于 Hadoop 的智能电网时序大数据存储处理中,根据云安全实现数据的安全存储。因云安全核心为密码技术与加固技术,由此能够通过密码技术保护智能电网时序大数据存储具有保密性与完整性[9 - 10]。其中,摘要信息为消息签名操作之后所得数据,密文为数据加密之后所得数据,密钥信息为针对数据加密过程中用到的密钥实行信息隐藏之后所得数据。
综上,数据加密存储的过程可表示以下几步:
步骤 1: 生成摘要,通过消息摘要算法针对需要存储的智能电网时序大数据生成相应数字摘要。
步骤 2: 加密数据,根据密钥生成函数获取随机密钥,同时利用该密钥针对待存储数据实行加密,获取对应密文。
步骤 3: 随机密钥隐藏,针对上述获取的随机密钥实行信息隐藏处理。
步骤 4: 存储密文,把密文存储至云中。
步骤 5: 保存有关信息数据,当密文成功存储至云之后,把上述步骤中获取的密钥和数字摘要两种信息并同文件名至 HBase 中,实现数据保存。
随机密钥信息隐藏过程中,以解决对称加密法密钥管理相关问题为目的,要针对随机密钥实行信息隐藏操作。加密为一种非常高效的信息隐藏策略。由此,为了针对随机密钥实行信息隐藏处理,设计如图 3 所示的密钥隐藏策略。
在上述策略中,通过数据源具备的各种属性和一个填充数即可生成摘要信息,然后利用 Hash 函数生成数据加密所需密钥。其中,属性中能够包括用户密码数据,在用户修改密码之后,可以使随机密钥也随之修改,无需重加密,能够有效提升效率。
结合随机填充数目的为避免字典攻击与预先计算攻击等安全问题。以增强保密性为目的,数据源属性组合信息和详细 Hash 应事先保密。以变电站为例,该变电站属性将 Substation 类属 性 当 作 标 准,设计的密钥生成架构如图 4 所示。
为了 把 密 钥、摘要两种信息存储至 HBase 中,对 表MetaTable 结构进行设计。
其中,MetaTable 主要分为三列,分别为行关键字 RowKey 应用至存储文件名称,时间戳 Timestamp 和列族 Metadata( 包括密钥信息与摘要信息的保存标签) 。除此之外,针对无需进行加密的数据而言,使用 hiddenKey 是全 0 进行区分。
采用 HBase 主要原因为电网中的数据采集及存储频率均非常高,一般关系数据库无法承受此种压力。HBase 查询效率不会随着数据库中的数据量规模变大降低,其为一个具有可伸缩性能的分布式存储系统。
数据读取过程为:
步骤 1: 数据读取,在分布式文件系统中读取密文,在 HBase 中将有关数据读取出来。
步骤 2: 确定数据类型,基于密钥信息,判断分布式文件系统中数据需要解密与否。假设密钥信息为 0,那么表明数据为明文,无 需 进 行 解 密,直 接 到 步 骤 4; 反 之,表 明 需 要解密。
步骤 3: 得到随机密钥,通过数据源属性,也就是密钥信息得到密 钥,同时针对密钥信息实行信息恢复获取随机密钥。
步骤 4: 对数据进行解密,利用上述获取的密钥针对密文实行解密。
步骤 5: 对数据完整性进行检查,生成密文数字摘要信息,同时和步骤 1 中的摘要信息进行对比,确定数据完整性。假设不一致,那么表示云中数据已经被篡改; 反之,说明数据正常。
3 实验结果与分析
为了验证基于 Hadoop 的智能电网时序大数据处理方法有效性,进行一次实验。实验在某省电科院实验室所搭建的 Hadoop 并行计算平台上完成,该平台由 23 个节点构成。节点物理配置的 CPU 为 8 核、内存为 32G,硬盘为 300G,网络为千兆以太网。实验过程中,文件备份为 3。
相关知识推荐:大数据方面的期刊杂志
实验分别以 CPU 利用率和数据安全性为验证指标。其中,以验证所提方法 CPU 利用率为目的,在大小不一的数据文件下开展实验,为避免时间因素导致实验结果带来的主观性,本次实验将分别在三台电脑上进行,并在规定时间内进行检测,测试时间为 19: 15 ~ 19: 33。依据智能电网数据量存在差异大的特性,分别取文件大小为 10MB、50MB、500MB 的条件下进行实验,所得实验结果如 6 所示。
分析图 5 可知,基于 Hadoop 的智能电网时序大数据安全存储处理与直接存储耗时相差不大,表现出了良好的运行性能,存储处理效率高。主要原因为数据存储过程中网络传输时间占据了主导地位,其它时间在数据量比较大时影响不是很大,且数据的清洗和分类均为高效率存储奠定了基础,有效提高了电网时序大数据存储速度。
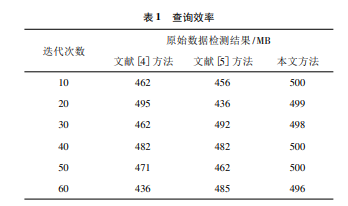
为进一步验证本文方法的处理安全性,本次实验将在 500MB 的数据文件中加入字典攻击与预先计算攻击,并设置攻击数据和异常数据大小为 20MB,检验本文方法是否能够有效、安全、准确的查询到系统原始数据,以此分析所提方法的安全性。实验结果如表 1 所示。
由表 1 可知,所提方法可高效抵御攻击,保障数据安全性。在数据加密存储过程中,结合了随机填充数目的为避免字典攻击与预先计算攻击等安全问题,并以增强保密性为目的,数据源属性组合信息和详细 Hash 也做了保密。
4 结束语
鉴于现实需求,提出基于 Hadoop 的智能电网时序大数据处理方法。在数据处理过程中,有效结合了数据清洗、分类、安全存储几个部分,并通过实验对该方法进行测试,结果显示,该方法抗攻击性能强,且耗时少,是一种可行的电网数据处理方法。下一步可将跨节点计算并行化方面当作重点进行研究,进一步提高数据处理效率。——论文作者:孙利宏
参考文献:
[1] 贺红燕. 基于大数据的智能电网关键技术研究[J]. 电源技术,2016,40( 8) : 1713 - 1714.
[2] 陈敬德,盛戈皞,吴继健,等. 大数据技术在智能电网中的应用现状及展望[J]. 高压电器,2018,54( 1) : 35 - 43.
[3] 葛磊蛟,王守相,瞿海妮. 智能配用电大数据存储架构设计[J]. 电力自动化设备,2016,36( 6) : 194 - 202.
[4] 曲朝阳,熊泽宇,颜佳,等. 基于 Spark 的电力设备在线监测数据可视化方法[J]. 电工电能新技术,2016,35( 11) : 72 - 80.
[5] 喻宜,吕志来,齐国印. 分布式海量时序数据管理平台研究[J]. 电力系统保护与控制,2016,44( 17) : 165 - 170.
[6] 张宇航,邱才明,杨帆,等. 深度学习在电网图像数据及时空数据中的应用综述[J]. 电网技术,2019,43( 6) : 1865 - 1873.
[7] 李俊楠,李伟,李会君,等. 基于大数据云平台的电力能源大数据采集 与 应 用 研 究[J]. 电 测 与 仪 表,2018,56 ( 12 ) : 104 - 109.
[8] 余容,黄剑,何朝明. 基于 SM4 并行加密的智能电网监控与安全传输系统[J]. 电子技术应用,2016,42( 11) : 66 - 69.
[9] 张思佳,顾春华,温蜜. 智能电网中的数据聚合方案分类研究[J]. 计算机工程与应用,2019,55( 12) : 83 - 89.
[10] 张子栋,张杰敏,茅剑. 大数据处理警示性图像颜色纹理特征选取仿真[J]. 计算机仿真,2019,36( 5) : 434 - 437,470.
* 稍后学术顾问联系您




